
AMD 向 Intel 投下 7nm 震撼弹 !! 全新 Zen 2 微架构、第 3 代 Ryzen 处理器正式登场,相较上代性能平均提升 15%、Cache 容量倍增,率先支援 PCIe 4.0 传输技术,优化 DDR4 记忆体控制器,加上 7nm 制程改进令时脉进一步提升,整体性能增长最高可达 21%。HKEPC 编辑部找来全新 AMD Ryzen 9 3900X 处理器,与同价位对手 Intel Core i9-9900K 作效能对比测试。
全新 7nm 制程、第 3 代 Ryzen 处理器登场
AMD 正式向 Intel 投下 7nm 核弹,推出全新 Zen 2 微架构、第 3 代 Ryzen 处理器,受惠于微架构改良 IPC 性能相较上代「Zen+」平均提升约 15%,加上全新 7nm 制程改进令核心时脉再提升 350MHz,令整体性能提升可达 21%。

更重要的是,全新 7nm 制程让 AMD 可以在现有的 Socket AM4 封装放进更多处理核心,以性价比及多核优势作卖点,相同 CPU 核心数规格售价较 Intel 便宜,相同价位下 CPU 核心更多、性能更高,相信有不少用家会转投 AMD 怀抱,进一步打破 INTEL 市场垄断局面。
回顾 AMD 这三年的进步,无论是制程及微架构都按照时程表发展并準时实现,在 Socket AM4 平台实现 3 个微架构及制程改良、CPU 核心数目提升 4x、PCIe 频宽提升 1x,记忆体频宽提升了 33%,相较 Intel 仍保持老旧的 14nm 制程,让 AMD 声势变得一时无两。
全新 AMD Zen 2 微架构
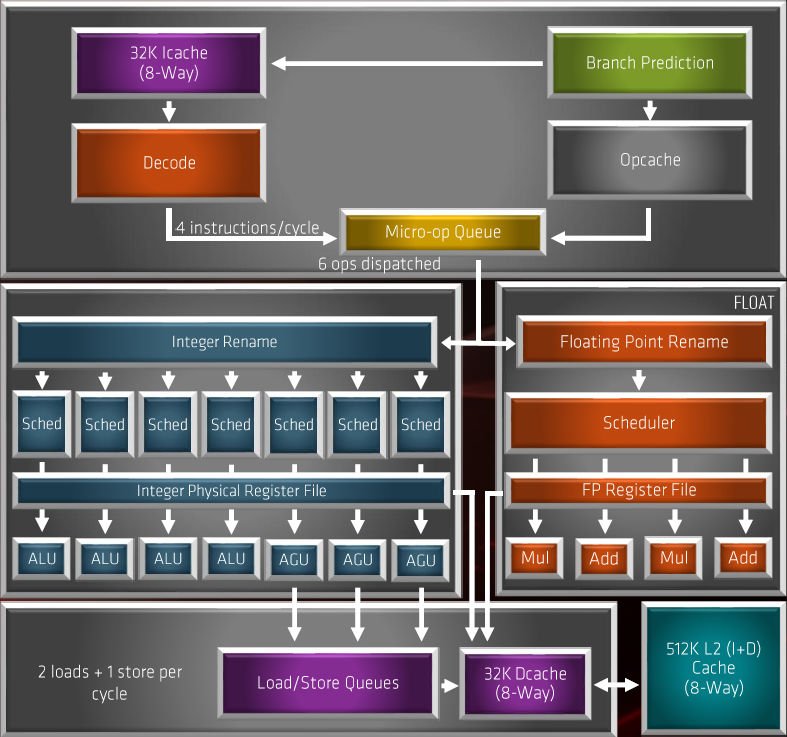
▲ AMD Zen 2 微架构 Block Diagram
相较上代「Zen+」微架构属于半代更新,仅针对 Cache 及记忆体系统作出改动,全新「Zen 2」微架构有着更明显的改良,包括了增加内部频宽、提升运算单元使用率、提升缓存命中率、提升单一週期指令执行数等等,主要改进及全新设计包括︰
→ 改用 256bit Single-Op 浮点单元
→ μOps Cache容量倍增至 4096 byte
→ 全新的 TAGE 预测分支设计
→ 增至 3 组 AGU 单元
→ 增加 Load/Store Bandwidth
→ L3 Cache 容量提升 1 倍
→ 改良 Fetch 及 Pre-Fetch 能力
→ 改良 ALU 及 AGU Schedulers
→ 增加 Register File 容量
→ IMC 控制器改良、提升至 DDR4-3200+
经改良的 Front End 引擎
全新 AMD Zen 2 微架构针对 Front End 引擎作出了不少改良,具备全新 TAGE Branch Predictor 单元设计,透过优化内部演算法去预测将被执行的指令,并寻找下个直接及间接目标,提早填充至 Request Queue 单元,有助降低运算延迟并优化记忆体系统并行性能。
AMD 扩大了 Zen 2 微架构的 Branch Target Buffer (BTB) 缓存,L1 BTB 由 256 增至 512 entries、L2 BTB 由 4096 增至 7,168 entries、ITA 增至 1024 entries,相较上代 Zen+ 有效降低约 30% 预测分支失败率。
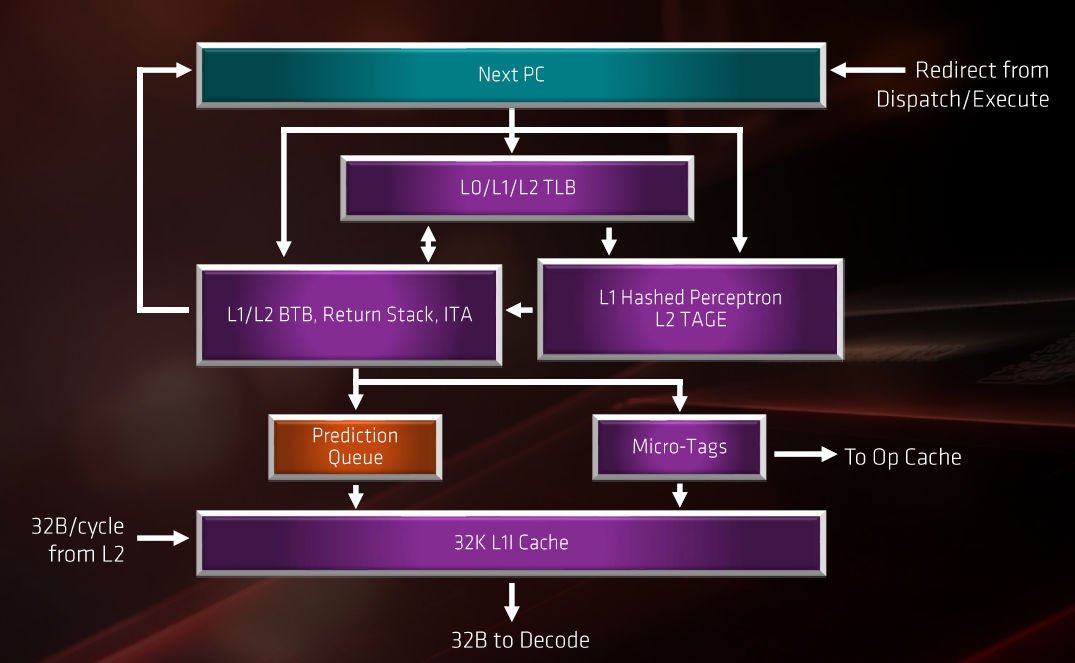
▲ AMD Zen 2 微架构的指令提取设计
此外, AMD Zen 2 微架构为提升 Micro-Tags 效率,将 μOps Cache 缓存的可储存指令量由上代 2,048 增加一倍 4,096 条,让更多解码后的 μOps 指令可被暂存,当遇上相同的 x86 指令时不需要再 Decoder 单元进行解码,直接由 μOps Cache 缓存单元提取 μOps 指令,为 Front-End 引擎提供更高的 x86 指令吞吐量。
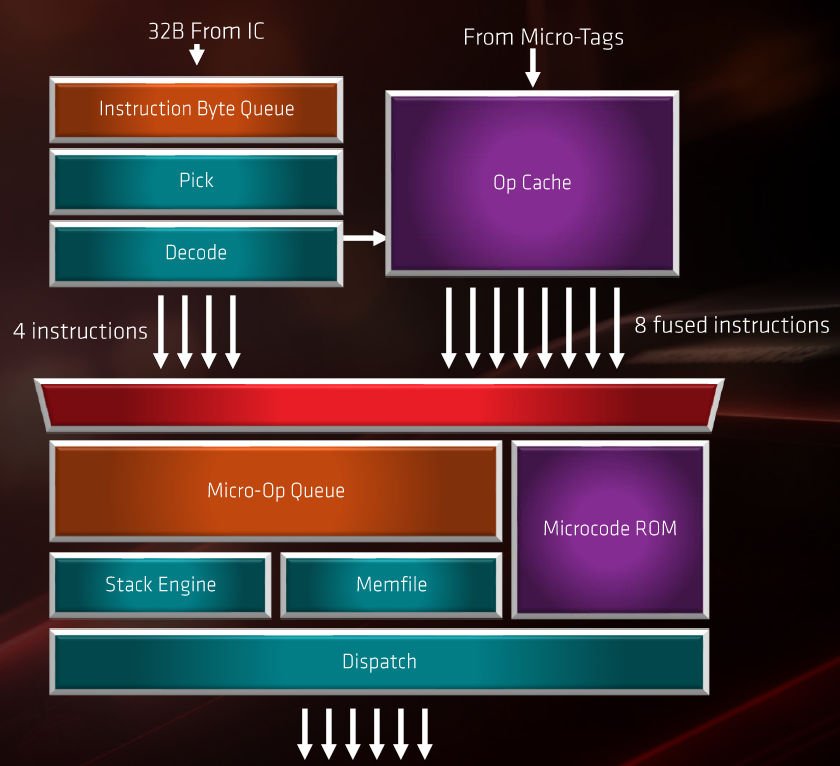
▲ AMD Zen 2 的 Front End 引擎
指令解码方面, AMD Zen 2 微架构的 Front-End 引擎沿用 1 组 4-Wide x86 Decoder ,每个週期可处理 4 个 x86 指令,但进一步改良了 Fast Path 设计,Decoder 单元支援更多 x86 操作指令可被融合成 1 个 μOps 指令,令运算效率进一步提升。
此外,AMD Zen 2 微架构亦将 μOps Cache 每个週期可提取的 μOps指令数目由 4 条增至 8 条,更多的 μOps 指令会被传送至 μOps Queue 列队单元等待分配,进一步提升处理器的 x86 指令吞吐量,更有利于 SMT 同步多线程运算效率。