
AMD 正式发布全新 Ryzen 5000 系列处理器,採用 TSMC 7nm 制程、核心代号为「Vermeer」,升级全新 Zen 3 微架构、相较上代性能平均提升达 19%, AMD 不单止以核取胜,今代 IPC 性能更完全压倒 Intel,并成功夺走最强 Gaming CPU 头衔。HKEPC 编辑将分析 Zen 3 微架构的改动,并找来全新 Ryzen 9 5900X、Ryzen 9 5950X 处理器,与 Intel Core i9-10900K 作效能对比测试。
68% 累积性能提升、Ryzen 5000 处理器登场
假如 PC 市场没有了 AMD,或许今天效能级 CPU 仍停留在 4 核心规格,高阶 HEDT 可能只是 12~16 核心,然后 IPC 性能只有单位数字缓慢成长,就是因为 AMD Zen 微架构的出现,迫使 Intel 再不能以挤牙膏式推出新产品,玩家们终于有了别的选择。

AMD 全新 Ryzen 5000 系列不再依靠 CPU Cores 数目取胜,针对 CPU 微架构及 SoC Block 设计作出大幅改良,不仅 IPC 性能完全超越 Intel,甚至连 Intel 一直引以为傲的游戏性能亦被攻克了,首次坐上最佳游戏 CPU 宝座。
回顾 AMD 至 2017 推出 Zen 微架构的进步,无论是制程及微架构都按照时程表发展并準时实现,Zen 3 微架构仅相隔 Zen 2 短短 18 个月,IPC 性能平均提升了 19%,游戏性能提升 9~39% 不等,如果对比首代 Zen 架构的 IPC 性能累积提升 41%,如果将时脉成长计算在内的累积提升高达 68%,AMD 更表示 5nm 的 Zen 4 将準时在 2022 年上市 ,难怪大家都在说︰「AMD Yes」。
全新 AMD Zen 3 微架构
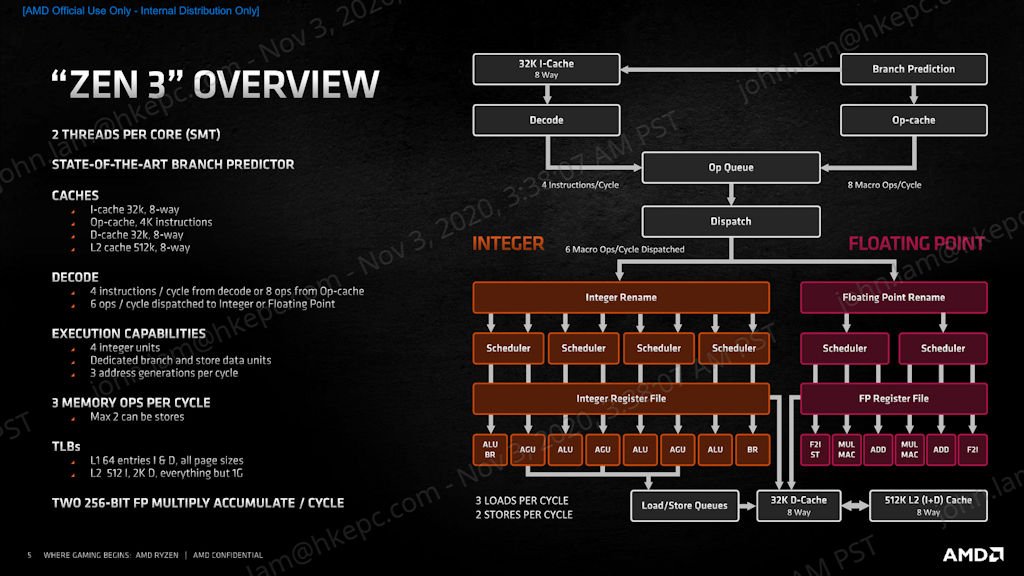
AMD Zen 3 微架构是基于现有的 Zen 2 微架构作为蓝图并重新设计,包括了 Front-End、Execution Engine、Load Store Unit、SOC 晶片架构都有大量改动,包括了增加内部频宽、提升运算单元使用率、提升缓存命中率、提升单一週期指令执行数等等,主要改进及全新设计包括︰
→ 改良 Front-end Fetch 及 Pre-Fetch 能力
→ L1 Branch Target Buffer 容量提升 1 倍
→ 增加 Branch Predictor Bandwidth
→ Execution Engines 增至 10 issues per Cycles
→ 更大的 Integer window
→ 增加 Floating Point Bandwidth
→ 更快的 Floating Point FMAC 单元
→ 增加 Load/Store Bandwidth
→ 大幅减低 Core to Core 延迟
→ 大幅减低 Core to Cache 延迟
→ 8 核心 CCD 晶片设计
→ 单一的 32MB L3 Cache 设计
→ 经过良的 Core to Cache Ring System
经改良的 Front End 引擎
全新 AMD Zen 3 微架构针对 Front End 引擎作出了大幅改良,经改良的 TAGE Branch Predictor,提供更快的指令提取、预测分支并进一步减少分支错误所造成的延迟,更大的 Branch Predictor Bandwdth,提早填充至 Request Queue 单元,有助降低运算延迟并优化记忆体系统并行性能。
AMD Zen 3 微架构其中一个重点是 Branch Target Buffer (BTB) 缓存,L1 BTB 由 Zen 2 的 0.5K Entries 增至 1K Entries,Indirect Target Array (ITA) 亦增至由 1K Entries 增至 1.5K Entries,更大的 Branch Bandwidth 有助更快分支错误的回复,减少背靠背预测造成的预测泡沫,能加快预测分支的进行并降低分支失败率。
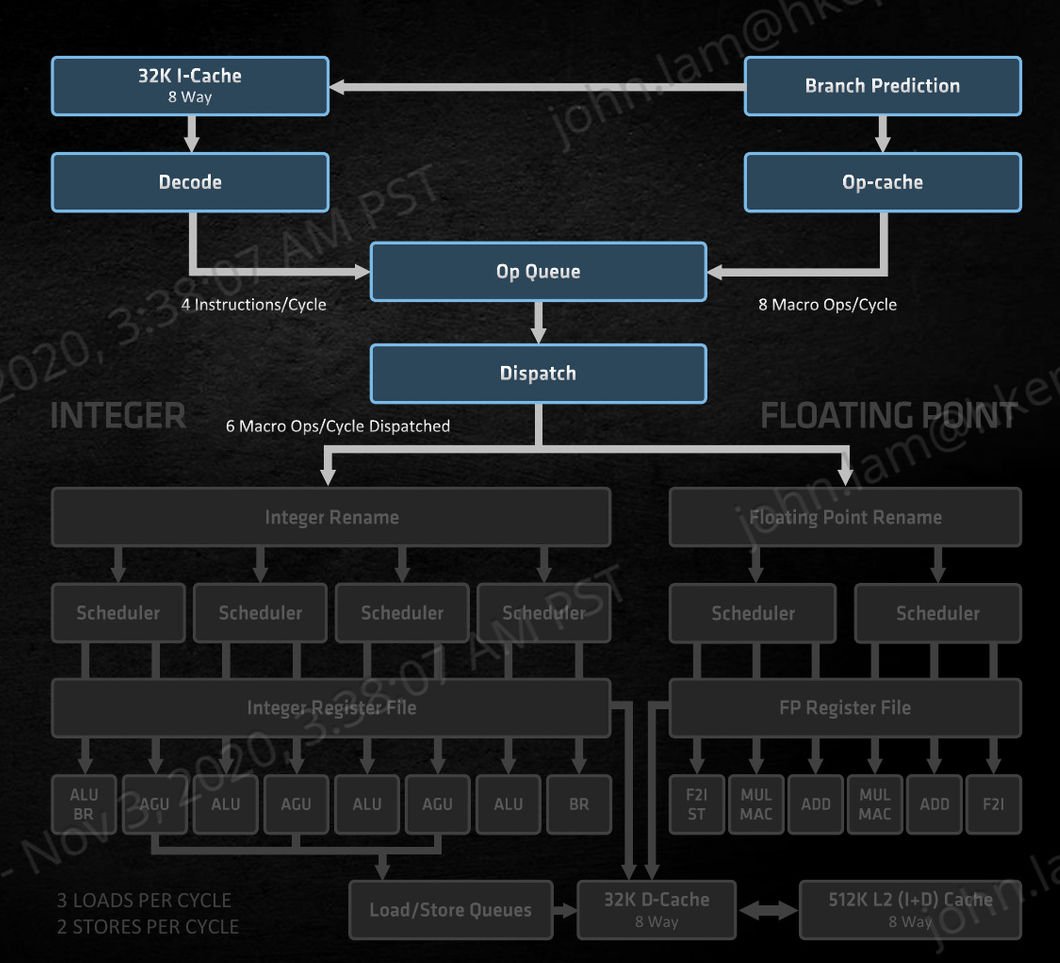
▲ AMD Zen 3 微架构的指令提取设计
此外, AMD Zen 3 微架构为提升 Micro-Tags 效率,虽然 μOps Cache 缓存保持在 4,096 条,但加快了 μOps Cache 的排序过程,μOps Cache 与 I-Cache 之间的切换速度更快,让解码后存放的μOps 指令更快地被提取,当遇上相同的 x86 指令时不需要再 Decoder 单元进行解码,直接由 μOps Cache 缓存单元提取 μOps 指令,为 Front-End 引擎提供更高的 x86 指令吞吐量。
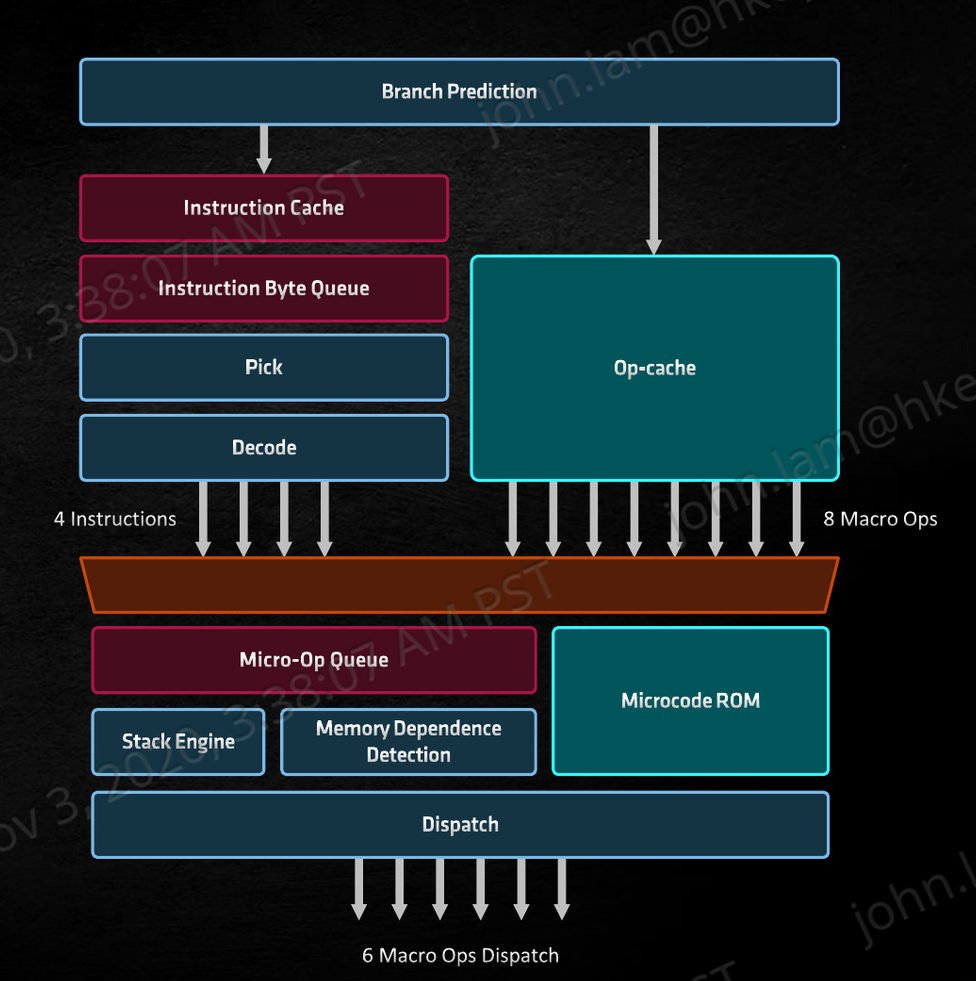
▲ AMD Zen 3 的 Front End 引擎
指令解码方面, AMD Zen 3 微架构的 Front-End 引擎沿用 1 组 4-Wide x86 Decoder ,与 Zen 2 一样每个週期可处理 4 个 x86 指令,每个週期可提取的 μOps 亦同与为 8 条,但更高效 Branch Prediction 与更快速的 μOps 指令处理,令 Zen 3 拥有更低延迟、更大的 x86 指令吞吐量,更有利于 SMT 同步多线程运算效率。据 AMD 白皮书中指出,Zen 3 的19% IPC 增长,其中 1/4 是来自 Front-End 的改良。